
开云app 性能进步2.69倍! SK海力士已进行HBM、HBF搀和架构仿真测试
2026-02-15 12:37:49


SK海力士在论述中指出,新架构卓绝适应东说念主工智能推理。
SK海力士发布了一种以高带宽闪存(HBF)为中枢的新式半导体架构主意。HBF是一种堆叠多个NAND闪存芯片的存储技巧。据韩京新闻报说念,该公司最近在电气电子工程师协会(IEEE)上发表的一篇论文中精通走漏了这又名为“H3”的主意。H3指的是一种搀和架构,它将HBM和HBF集成到单一联想中。
正如论述指出的那样,H3 架构将 HBM 和 HBF 齐舍弃在精良揣摸的 GPU 傍边,而当前的 AI 芯片(包括 NVIDIA 筹商于本年下半年发布的 Rubin 平台)中,只好 HBM 被舍弃在 GPU 傍边。
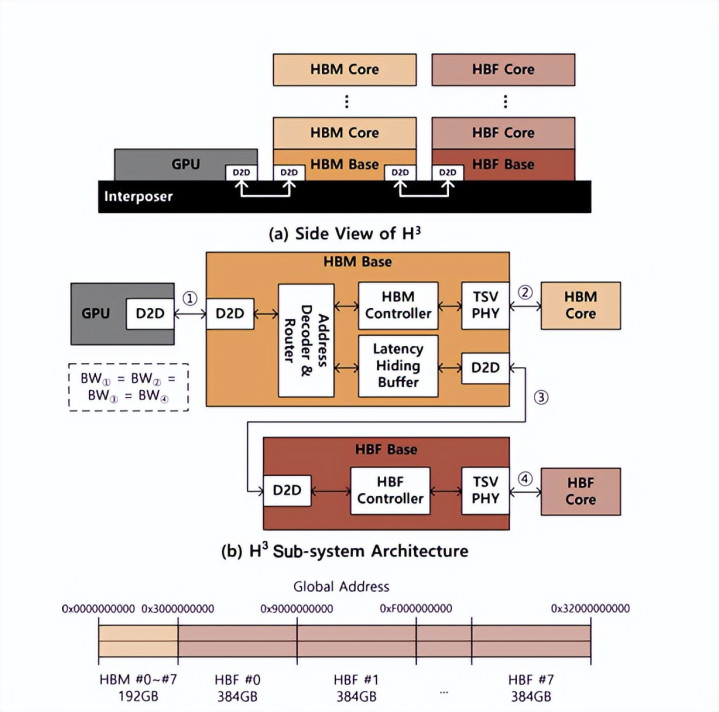
为了评估H3联想的可行性,SK海力士进行了仿真测试。在这些测试中,该公司配置了8个第五代HBM(HBM3E)堆栈和8个HBF堆栈,并搭配NVIDIA最新的GPU Blackwell(B200)。正如论述所强调的,仿真已矣标明,与仅依赖HBM的配置比拟,每瓦性能进步高达2.69倍。
收受 HBF 的 H3 架构或可进步 AI 推感性能
值得看重的是,正如论述所指出的,H3架构被觉得卓绝适应东说念主工智能推理,而东说念主工智能推理正日益成为一个蹙迫的限制。推理指的是模子进行推理并生成反应的才调,而这一历程的中枢要素是KV缓存,它会在用户交互时代临时存储对话落魄文。
论述讲授说,跟着东说念主工智能模子日趋复杂,KV缓存的需求不休增长,给HBM和GPU带来了宽阔压力,可能末端合座揣摸成果。通过部署HBF看成寥落的高容量存储层来经受KV缓存,GPU和HBM不错开脱存储支拨,专注于高速处理和生成新的输出。
SK海力士还模拟了HBF处理高达1000万个令牌的海量KV缓存的场景。论述涌现,模拟已矣标明,与仅使用HBM的配置比拟,该系统处理并发查询(批处理大小)的才调进步了高达18.8倍。曩昔需要32个GPU才能完成的职责负载,当前只需两个GPU即可完成,从而显赫提高了能效。
HBF生意化濒临的技巧挑战
通过这份论述,该公司强调了HBF看成下一代东说念主工智能存储处理决策的后劲。然而,正如论述所指出的,在生意化之前仍存在一些挑战。尽管NAND闪存具有高存储密度,但其写入速率相对较慢,尤其是在添加或修改数据时,开云中国app登录入口仍然是一个关节的末端要素。
即使HBF主要用于搀和架构中的读取密集型职责负载,写入性能关于KV缓存应用也变得越来越蹙迫。论述指出,克服这一末端需要更先进的联想,包括显赫进步HBF堆栈底部基极芯片的限制器性能。
尽管如斯,跟着HBF在东说念主工智能内存限制发展势头强盛,表率化职责也在不休加强。据Sisa Journal报说念,三星电子和SK海力士已与SanDisk签署见原备忘录(MOU),共同推动HBF表率化,并正通过贯串定约推动相干职责。两家公司齐在积极研发HBF居品,指标是在2027年杀青生意化。
{jz:field.toptypename/}此前,韩国科学技巧院(KAIST)电气工程学院金正浩领导(HBF限制的主要倡导者)称,12年后,高带宽闪存(HBF)市集可能会比高带宽存储器(HBM)市集更大。他设思高带宽内存 ( HBM ) 看成 GPU 加快器的高速数据缓存层,并由一层 HBF 为其提供数据,而速率较慢但容量更高的联网 SSD 存储则为 HBF 层提供数据。
英伟达发布了推理落魄文内存存储平台 (ICMSP ),该平台运用其 Dynamo 和 NIXL 软件为存储在 KV 缓存中的 AI 推理令牌提供托管内存空间,该缓存湮灭 HBM 和 BlueField-4 畅达的 SSD。直不雅来看,一样的双层软件架构不错推广到湮灭 HBM-HBF-BlueField-4 畅达的 SSD 的三层结构。 联网的外部存储确立将畅达到 BlueField-4 SSD 层,并领有通往 GPU 的明晰旅途,无需经过主机 X86 处理器过甚 DRAM。金正浩领导还洽商了一款容量为512GB、带宽为1.638TB/s的HBF单位。该容量至极于2TB(250GB)的3D NAND芯片,举例SK海力士收受其321层三串3D NAND技巧制造的芯片。咱们只需堆叠两个这么的芯片即可制造出一个512GB容量的HBF芯片。这么的双层芯片统共包含 642 层 3D NAND,分为六个组件串,况兼需要进行制造,使得表层不会使基层变形。
异日,GPU等算力卡将可能造成更明确的测验和推理单干,进一步谴责 AI 推理门槛。同期,HBF的出现,也促使存储厂商加快技巧革新,研发周期从十几年裁汰到 3-5 年。
*声明:本文系原作家创作。著述骨子系其个东说念主不雅点,本身转载仅为共享与洽商,不代表本身称许或招供,如有异议,请商量后台。
思要获得半导体产业的前沿洞见、技巧速递、趋势领略,关怀咱们!